shaktistanwar
India

I will provide further details to anyone who wants to enter the contest. This contest is intended to help me with ideas and also to find and hire the right person to develop this product for me moving forward.
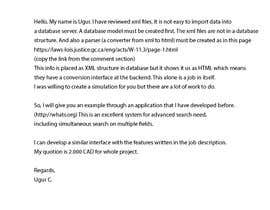
I am developing a product that will pull information from existing XML text data sources, store it in a database and generate a front-end for people to search based on various parameters. The XML is open source Canadian government legislation (see https://laws-lois.justice.gc.ca/eng/FAQ/) (which provides a link to the Canadian legislation XML publicly available open source information) and has many many parameters and identifies iterations and amendments to the text of the documents over time so this will not be a simple task. That's it for now. All ownership of the project and all rights will be owned by me.
The initial government legislation will be the Canadian Act: Proceeds of Crime(Money Laundering) and Terrorist Financing Act and
5 Regulations related to this Act:
1. Proceeds of Crime (Money Laundering) and Terrorist Financing Regulations
2. Proceeds of Crime (Money Laundering) and Terrorist Financing Suspicious Transaction Reporting Regulations
3. Cross-Border Currency and Monetary Instruments Reporting Regulations
4. Proceeds of Crime (Money Laundering) and Terrorist Financing Registration Regulations
5. Proceeds of Crime (Money Laundering) and Terrorist Financing Administrative Monetary Penalties Regulations
You can find all these in the XML data file that is open to the public using the address at the link address provided above.
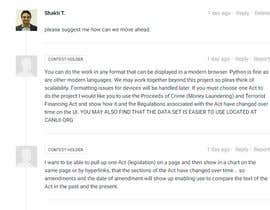
Note that many of the regulations refer to sections in the main Act and when looking up a section of the Act I would like to have an option to see related regulations. Similarly in reverse if you look at a section in a regulation I would like to have an option to see the related section in the Act.
Evaluation will be based on:
- Accuracy and completeness;
- Visual appeal of the front end interface;
- Flexibility of the search capacity;
- Functionality of the visual front-end UI;
- Overall UX;
- Any visual analytics or data visualization component (timeline for amendments enabling user to see when amendments were made to one or more legislative changes);
- Ability to scale to additional legislative XML text sources using the same schema;
- Ability to monetize and sell access to the tool with updates on a subscription model or export it and sell it as a package;
- Surprise me...

あなたのコンテストを投稿 速くて簡単

たくさんのエントリーを集めましょう 世界中から

ベストエントリーをアワード ファイルをダウンロード - 簡単!